ビデオOCRを使用してビデオからテキストを無料で抽出する方法:2026年ガイド

30分のソフトウェアデモを録画しました。すべてのメニュー項目、コードスニペット、警告メッセージが画面にはっきりと表示されています。しかし、問題があります。その貴重な情報はすべてビデオの中に閉じ込められており、検索、コピー、編集ができません。
ここで、ビデオOCR(光学文字認識)がすべてを変えます。これは、ビデオフレームをスキャンし、表示されているすべてのテキストを「読み取り」、編集可能で検索可能なドキュメントに変換するテクノロジーです。画面を一時停止して、表示されているものを手動で再入力する必要はもうありません。
このガイドでは、ビデオOCRの背後にある複雑なテクノロジーを説明し、最新のビデオOCRソフトウェアを使用して、自分で簡単にワンクリックで実行する方法を紹介します。
クイック回答:オンラインでビデオOCRを使用する最も簡単な方法
はい、ビデオからすべての視覚テキストを簡単に抽出できます。
最適な方法は、ScreenAppのようなオールインワンのビデオOCRオンラインプラットフォームを使用することです。ビデオ(サイレントビデオでも)をアップロードするだけで、ビデオOCR機能がすべてのフレームをスキャンし、画面上のすべてのテキストを認識して、完全な編集可能なドキュメントを提供します。これは、当社のビデオからドキュメントへの変換パイプラインの核となる部分です。

ビデオOCRはどのように機能しますか? (技術的なプロセス)
ワンクリックツールのシンプルさを理解するには、開発者がゼロから構築する必要がある複雑なマルチステッププロセスを理解すると役立ちます。これは、ビデオからテキストを抽出するときに内部で起こっていることです。
ビデオ前処理(フレーム抽出)
ビデオは個々の画像(フレーム)に分割されます。開発者は、数秒ごとにフレームをキャプチャするために、OpenCV(ビデオOCR Python)のようなライブラリを使用することがよくあります。これにより、テキストを分析できる数百または数千のスクリーンショットが作成されます。
画像前処理(強調)
各フレームは、グレースケールに変換し、コントラストを高め、ノイズを低減することで、精度を高めるために最適化されています。これにより、テキストが背景に対して明確に際立ち、Tesseract OCRのドキュメントによると、認識精度が約70%から95%以上に向上します。
テキスト検出とローカリゼーション
AIは各フレームをスキャンして、テキストが表示される場所を見つけ、すべての単語の周りに「バウンディングボックス」を描画します。このテキスト検出フェーズでは、テキスト領域を読み取る前に識別し、誤検出を大幅に削減します。
光学文字認識(「OCR」)
分離されたテキスト領域は、OCRエンジンによって処理されます。最も有名なオープンソースエンジンはTesseract OCRです。Google Cloud Vision APIやAmazon Textractのようなクラウドプラットフォームは、個々の文字だけでなく、コンテキストを理解するより高度なディープラーニングモデルを使用しています。
後処理と統合
最後に、すべてのフレームからのテキスト抽出が結合され、重複が削除され、AIがタイムスタンプ付きの単一のクリーンなドキュメントに出力をフォーマットします。このステップでは、何千もの断片化されたテキストスニペットが1つのまとまりのあるドキュメントに変換されます。
開発者向け:独自のビデオOCRの構築
カスタムソリューションを構築する場合は、Python、OpenCV、Tesseractを組み合わせた多くのビデオOCR GitHubプロジェクトが見つかります。人気のあるリポジトリには以下が含まれます。
- pytesseract - TesseractのPythonラッパー
- PaddleOCR - 多言語OCRツールキット
- EasyOCR - 80以上の言語で使用可能なOCR
「簡単な方法」:ScreenAppでビデオからテキストを抽出する方法
複雑さを理解したところで、ワンクリックで5つのステップすべてを完了する方法を紹介します。ScreenAppのビデオからドキュメントへのパイプラインは、プロセス全体を自動化します。
これは、当社のビデオOCRオンラインツールを使用して、ビデオを検索可能で編集可能なテキストドキュメントに変換するための完全なワークフローです。
- ビデオをアップロード
- OCRオプションを選択
- 生成
- ダウンロード
ビデオファイルをアップロード
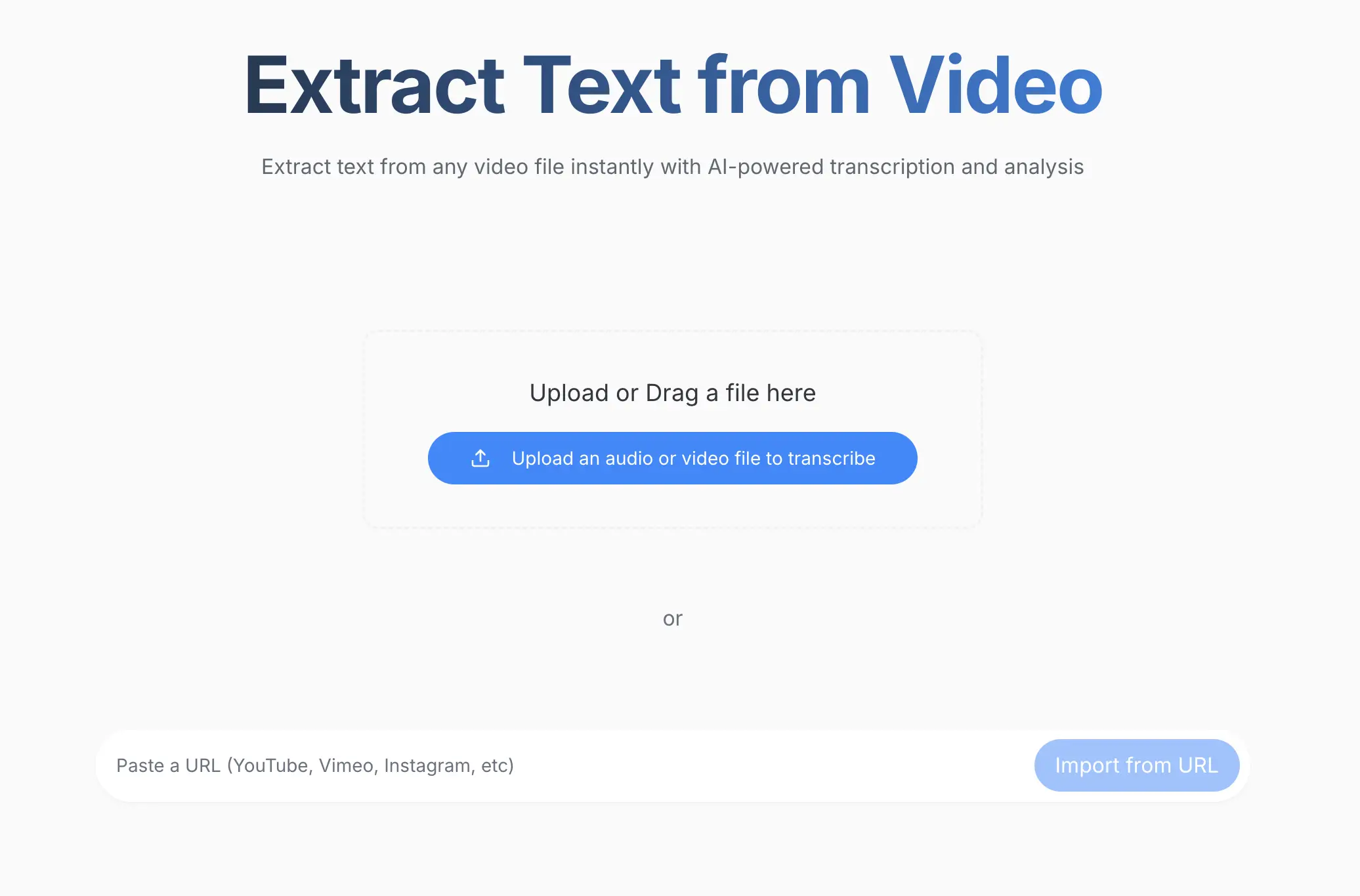
ビデオファイルをドラッグアンドドロップするか、リンク(YouTube、Googleドライブなど)を貼り付けるか、「ファイルをアップロード」ボタンを使用して、サイレント画面録画、プレゼンテーション、またはその他のビデオ形式を選択します。
サポートされている形式:
このプラットフォームは、すべての主要なビデオ形式とクラウドストレージ統合をサポートしているため、あらゆるソースからの既存のコンテンツを簡単に操作できます。ScreenAppダッシュボードにログインして、開始してください。
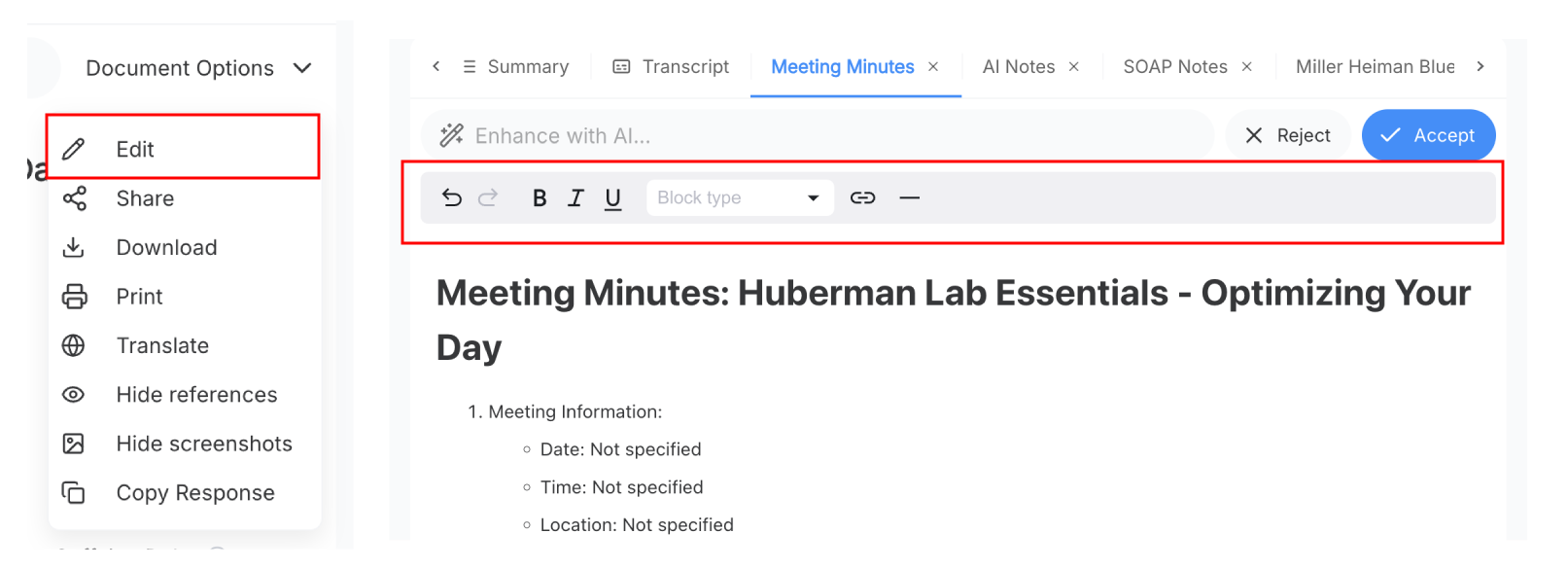
ビデオOCRを選択して有効にし、テキストを抽出
.webp)
ここで、ScreenAppのビデオOCRソフトウェアが引き継ぎます。アップロードすると、いくつかのAIオプションが表示されます。ビデオOCRの場合は、ビデオ分析(OCR)オプションを選択する必要があります。これにより、AIに視覚的なテキスト認識パイプラインをアクティブにするように指示します。当社のビデオからテキストへの抽出は、完全なテキスト抽出のためにOCRと音声文字変換を組み合わせます。
音声文字変換
高い精度で発話されたナレーションを文字変換します(オプション)
視覚テキスト認識
高度なOCRテクノロジーを使用して、画面上のすべてのテキストを読み取ります
フレームごとの分析
すべてのフレームをスキャンして、表示されているすべてのテキストをキャプチャします
テキスト統合
抽出されたテキストを1つの検索可能なドキュメントに結合します
プロのヒント
サイレント画面録画の場合は、OCR(画面からテキストを読み取る)ボックスを必ずオンにしてください。これは、音声のないビデオに不可欠です。AIが視覚テキストのみからドキュメントを作成できるためです。また、音声と画面上のコンテンツの両方を含むビデオの場合は、OCRと音声文字変換を組み合わせることもできます。
「生成」をクリックして、AIに作業させます

ワンクリックで、ScreenAppのビデオOCRソフトウェアが上記で説明した5つの複雑なステップすべてを自動的に実行します。AIは以下を実行します。
- • 最適な間隔でビデオからフレームを抽出
- • テキストの明瞭さを高めるために各フレームを前処理
- • バウンディングボックスを使用して、すべてのテキスト領域を検出してローカライズ
- • 各テキスト領域でOCRを高精度で実行
- • 抽出されたすべてのテキストを、タイムスタンプ付きの1つのクリーンなドキュメントに統合
わずか数分で、当社のAIがビデオフレームから完全なテキストドキュメントを構築します。処理時間はビデオの長さに依存し、ほとんどのビデオで通常2〜5分です。
編集可能なドキュメントをダウンロード
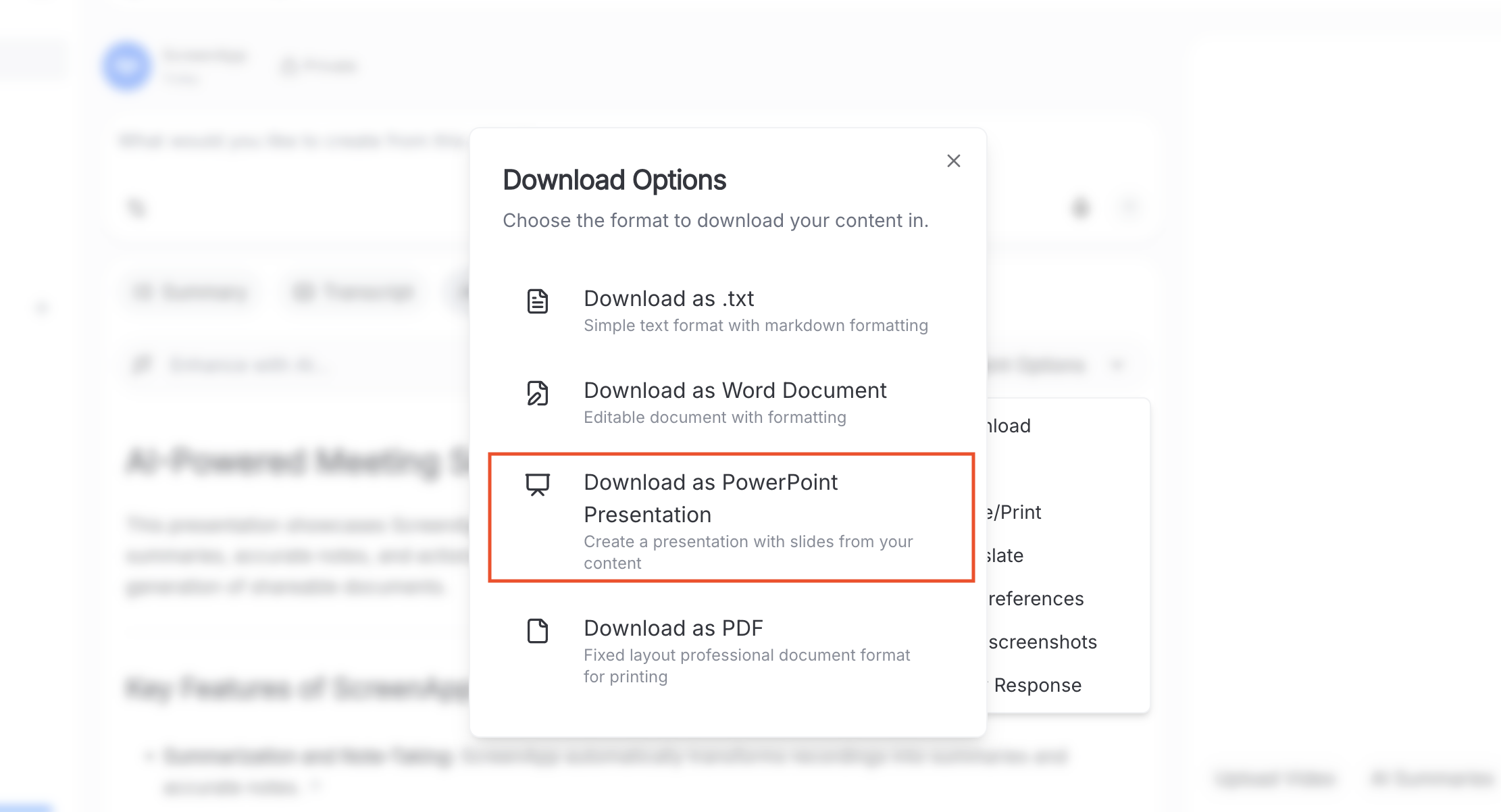
テキスト抽出が完了しました。「ダウンロード」ボタンをクリックして、抽出されたテキストを複数の形式で受信します。当社のビデオからテキストへの変換機能の詳細をご覧ください。
インタラクティブ機能:エクスポートされたドキュメントには、元のビデオに各テキストが表示された正確な時刻を示すタイムスタンプが含まれています。これにより、検証または追加のコンテキストのために特定の瞬間に簡単に参照できます。

これは誰のためですか? (ビデオOCRの主要なユースケース)
ビデオOCRは単なる目新しさの機能ではありません。業界全体で現実的でイライラする問題を解決します。最も価値を得ているチームは次のとおりです。
トレーニング - HRチーム
ソフトウェアチュートリアルのサイレント画面録画を書面によるSOPに変換します。すべてのクリックを手動で文書化する必要はありません。画面を録画し、ビデオOCRを実行して、完全なステップバイステップガイドを入手してください。
学生 - 教育者
手動でコピーせずに、講義のプレゼンテーションスライドからすべてのテキストを抽出します。講義を録画しましたか? ビデオOCRオンライン無料を使用して、すべてのスライドのコンテンツを即座にメモに取り込みます。
マーケター - 研究者
競合他社のビデオ、ユーザー生成コンテンツ、またはYouTubeビデオから画面上のテキストを分析します。ビデオからテキストを抽出して、データセットを構築し、メッセージングトレンドを追跡し、UIパターンを分析します。
最高の代替ビデオOCRソフトウェア - ツール
全体像を把握するために、ビデオからテキストへの抽出のための他の評判の良いツールを以下に示します。それぞれに、技術スキルとユースケースに応じて異なる強みがあります。
Google Cloud Vision API
強力な、開発者向けのAPI
Google Cloud Vision APIは、高精度のテキスト検出を提供し、Google Cloud Video Intelligenceテキスト検出のような機能をサポートしています。ビデオファイルを直接処理し、タイムスタンプとバウンディングボックスでテキストを抽出できます。ただし、コーディングの知識とAPI統合が必要です。
最適
高い精度要件を持つカスタムアプリケーションを構築する開発者
価格
従量課金制(無料枠あり、その後1,000画像あたり$1.50)
Tesseract OCR(PythonおよびGitHubを使用)
最高の無料のオープンソースオプション





