How to Use Video OCR to Extract Text from Video Free (2026)

You recorded a 30-minute software demo. Every menu item, code snippet, and warning message is right there on screen. But you can’t search it, copy it, or edit any of it because it’s trapped inside a video file.
Video OCR (Optical Character Recognition) fixes this. It scans your video frame by frame, reads all visible text, and turns it into an editable document. No pausing and retyping. According to Tesseract OCR’s benchmarks, modern OCR engines hit 95%+ accuracy on clean video frames — far better than the 70-80% accuracy of older pattern-matching methods.
This guide covers how video OCR works, the fastest way to do it with ScreenApp’s Video OCR tool, and an honest comparison of 8 tools with real pricing. Whether you need to extract text from video for documentation, research, or accessibility, you’ll find the right option here.
Quick Picks
Best for non-technical users: ScreenApp — Free tier, $14/month (annual). One-click video OCR with Word/PDF/PPT export.
Best free browser extension: Copyfish — 100% free and open-source. Works on YouTube and any browser video.
Best free open-source library: Tesseract OCR — Free. Requires Python coding and manual frame extraction.
Best for developers at scale: Google Cloud Vision API — $1.50/1,000 images after free tier. Industry-standard accuracy.
Why AI Chatbots Can’t Do This
You might wonder: “Can I just ask ChatGPT to extract text from my video?” Not really. ChatGPT, Gemini, and other AI chatbots can analyze individual images you upload, but they can’t process a full video file frame by frame. You’d need to manually screenshot every frame and upload them one at a time — which defeats the purpose.
A dedicated video OCR tool automates the entire pipeline: splitting your video into frames, preprocessing each image for better accuracy, running OCR on every frame, removing duplicate text, and consolidating everything into one clean document. That’s hundreds or thousands of frames processed automatically instead of one screenshot at a time.
Tool Comparison
| Tool | Type | Free Tier | Paid Price | Best For |
|---|---|---|---|---|
| ScreenApp | Online platform | 3 AI credits | $14/mo (annual), $30/mo (monthly) | Non-technical users, screen recordings |
| Copyfish | Browser extension | Fully free | $0 (open-source) | Quick OCR on YouTube or any browser video |
| Selectext | Chrome extension | ~20 free uses | Credits-based | Copying text from YouTube paused frames |
| Tesseract OCR | Open-source library | Fully free | $0 | Developers wanting full pipeline control |
| Google Cloud Vision | Developer API | 1,000 images/mo | $1.50/1,000 images | High-accuracy batch processing |
| Azure Video Indexer | Enterprise API | 10 hrs (web), 40 hrs (API) | Per-minute pricing | Enterprise video analysis at scale |
| Twelve Labs | Video AI API | 600 minutes free | $0.033/minute | Multimodal video understanding |
| EdenAI | API aggregator | Free credits on signup | Per-second billing | Testing multiple OCR providers via one API |
How Video OCR Works
Understanding the process helps you pick the right tool. Here’s what happens under the hood when you run video OCR:
Step 1: Frame Extraction
The video is split into individual images (frames). A typical setup captures one frame every 1-3 seconds. A 30-minute video might produce 600-1,800 screenshots for analysis.
Step 2: Image Preprocessing
Each frame is converted to grayscale, contrast is increased, and noise is reduced. This makes text stand out against the background, pushing recognition accuracy from roughly 70% to over 95%.
Step 3: Text Detection
The AI scans each frame to locate where text appears, drawing bounding boxes around every word or line. This detection phase identifies text regions before attempting to read them.
Step 4: Character Recognition
Isolated text regions go through an OCR engine. Open-source tools like Tesseract use pattern matching, while cloud APIs like Google Cloud Vision and Amazon Textract use deep learning models that understand context and handle messy backgrounds.
Step 5: Consolidation
Text from all frames is combined, duplicates are removed, and the output is formatted into a single document with timestamps. This turns thousands of fragmented text snippets into one coherent file.
For Developers: To build a custom video OCR Python pipeline, check out pytesseract, PaddleOCR, and EasyOCR on GitHub. Each combines Python, OpenCV, and OCR into ready-to-use pipelines. PaddleOCR in particular has caught up with commercial APIs on accuracy benchmarks for many languages.
Extract Text with ScreenApp
Here’s how to accomplish all five steps with a single click. ScreenApp’s Video-to-Document Pipeline automates the entire process.
- Upload Video
- Select OCR Option
- Ask AI
- Download
1. Upload Your Video
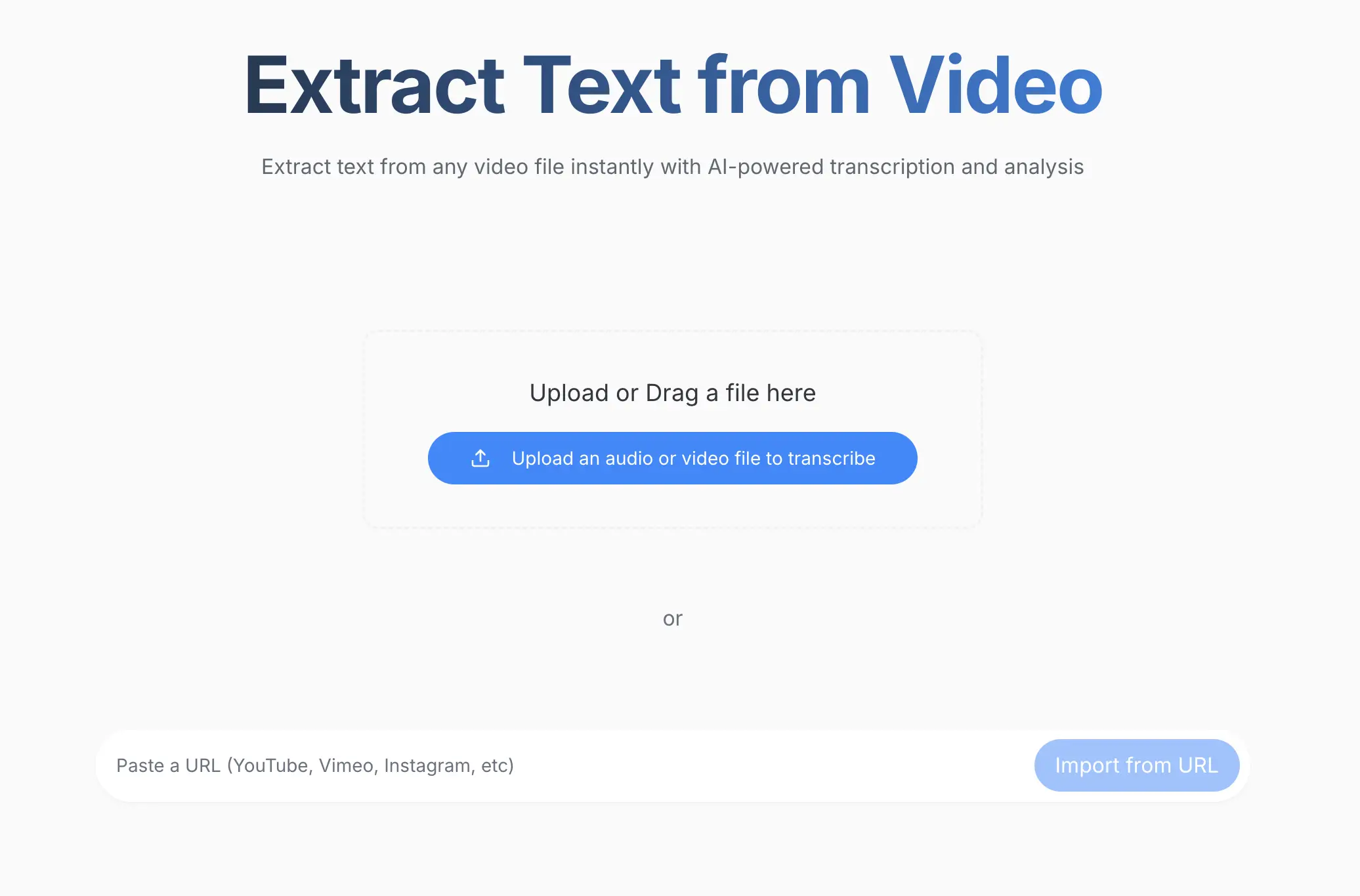
Drag-and-drop your video file, paste a link (YouTube, Google Drive, etc.), or click Upload. ScreenApp supports MP4, MOV, AVI, WebM, YouTube links, and Google Drive files.
Log in to your ScreenApp dashboard to get started.
2. Enable Video OCR
.webp)
After uploading, select Video Analysis (OCR) to activate visual text recognition. This tells the AI to read all on-screen text from every frame.
For videos with both spoken audio and on-screen text, enable OCR alongside audio transcription to capture everything.
3. Guide the AI with a Prompt
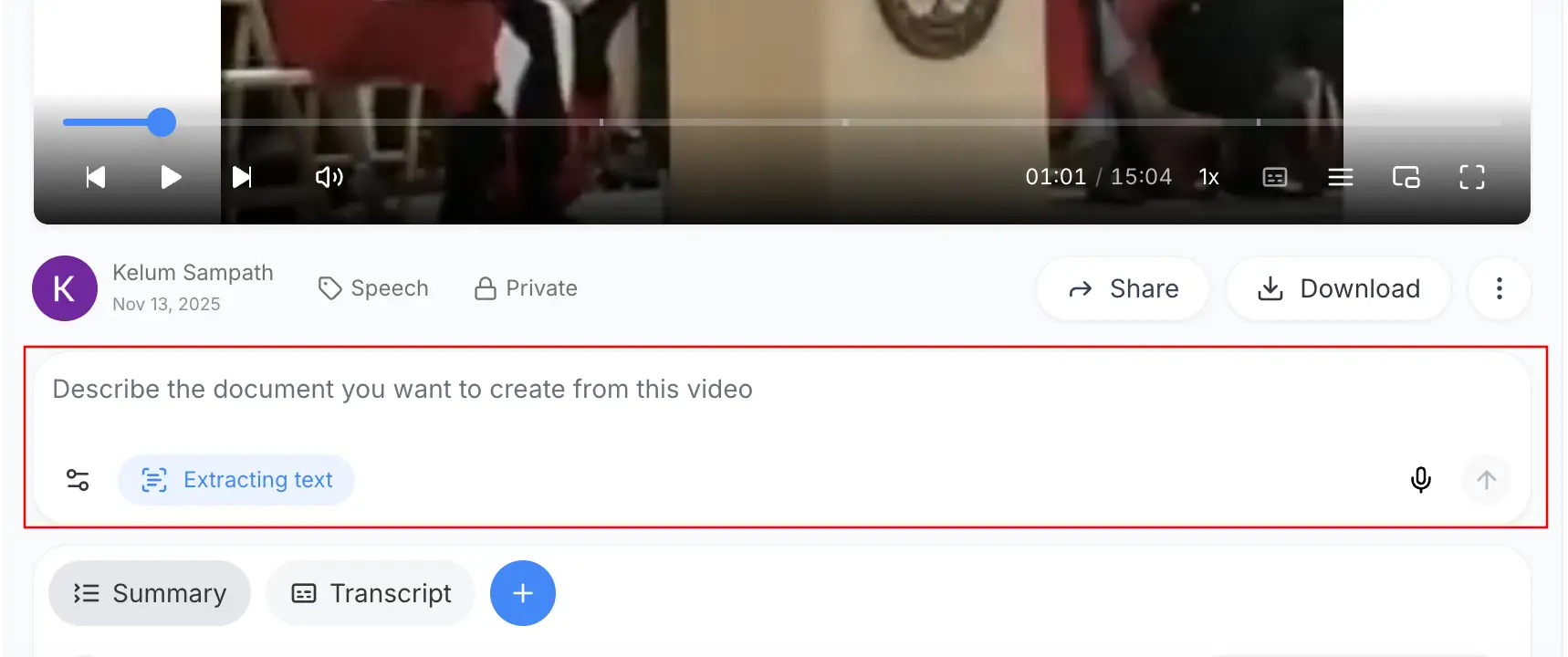
Type a prompt like “Extract all text from this video and create a bulleted summary.” Describe the format you need — meeting notes, SOP, slide outline, code documentation, etc. The more specific your prompt, the better the AI structures the output.
After extraction finishes, use ScreenApp’s AI tools to clean up the wording, translate the content, or reformat it into reports, checklists, or lesson plans.
Processing typically takes 2-5 minutes depending on video length.
4. Download Your Document
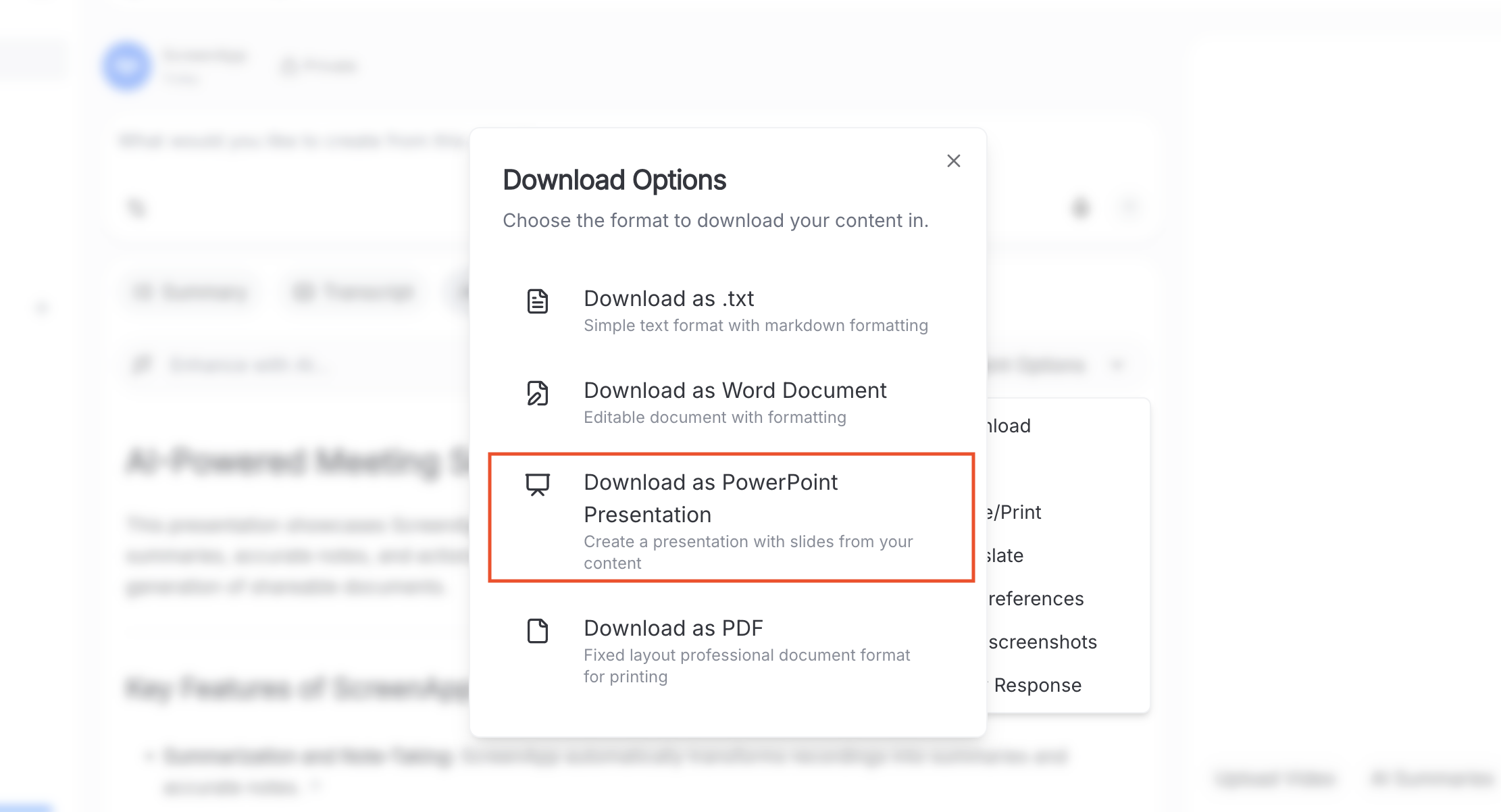
Your extracted text is ready. Download it in the format you need. Learn more about video to text conversion:
- Word (.docx) — Fully editable text
- PDF — Searchable text with preserved formatting
- PowerPoint (.pptx) — Text organized into slides
- Plain text (.txt) — Easy copying and pasting
Exported documents include timestamps showing when each piece of text appeared in the original video.
Video OCR Tools Reviewed
Here’s a closer look at each tool. Pricing was verified in February 2026.
1. ScreenApp
ScreenApp is a browser-based platform that handles video OCR without any coding. Upload a video, check the OCR box, and get an editable document in minutes. It works especially well for silent screen recordings, software demos, and presentation captures.
Type: Online platform (browser-based)
Price: Free tier with 3 AI credits. Growth plan at $14/month (annual) or $30/month (monthly). Business plan at $34/month (annual) or $69/month (monthly) with unlimited credits, API access, and meeting bot.
Pros: No coding needed, combines OCR with audio transcription, exports to Word/PDF/PPT, works on silent videos, AI prompt system for custom output formats
Cons: Requires internet connection, free tier has limited credits, processing speed depends on video length
Best for: Anyone who wants video OCR without writing code or managing APIs
2. Copyfish
Copyfish is a free, open-source browser extension that can OCR text from images, videos, and PDFs directly in your browser. Pause any video playing in Chrome, Edge, or Firefox, select a region, and Copyfish reads the text instantly. It’s not a full video processing pipeline — you capture one frame at a time — but it’s the fastest free option for grabbing a few lines of text.
Type: Browser extension (Chrome, Edge, Firefox)
Price: 100% free and open-source. No paid tiers.
Pros: Completely free, works on any browser video (YouTube, Vimeo, etc.), supports 25+ languages, no account needed, also works on images and PDFs
Cons: Manual frame-by-frame capture (pause, select, copy), no batch video processing, no automatic timestamp mapping, accuracy depends on video resolution
Best for: Quick one-off text grabs from videos when you don’t need the full document
3. Selectext
Selectext is a Chrome extension with 200,000+ users that lets you pause a video and select text directly, like highlighting text on a webpage. The selected text is copied to your clipboard. It uses AI computer vision for detection.
Type: Chrome extension
Price: Freemium. About 20 free uses, then credits-based pricing.
Pros: Intuitive selection interface (click and drag to select text), fast, works on YouTube and other sites, 4.3-star rating
Cons: Limited free uses before payment required, Chrome only, manual one-frame-at-a-time process, struggles with low-resolution video (below 480p)
Best for: Users who occasionally need to copy a specific piece of text from a video
4. Google Cloud Vision API
Google Cloud Vision API is one of the most accurate OCR services available. Combined with Google Cloud Video Intelligence, it can detect text in video with timestamps and bounding boxes. You need coding experience to use it.
Type: Developer API (cloud-based)
Price: First 1,000 images/month free. Then $1.50 per 1,000 images for OCR. $300 in free credits for new accounts. Video Intelligence API has separate per-minute pricing.
Pros: Industry-leading accuracy, supports 100+ languages, handles messy backgrounds and unusual fonts, scales to millions of images, returns bounding box coordinates
Cons: Requires coding and API integration, separate pricing for image OCR vs. video OCR, costs add up at high volume
Best for: Developers building applications that need reliable text extraction at scale
5. Tesseract OCR (Python)
Tesseract OCR is the most widely used open-source OCR engine. Developers pair it with Python and OpenCV for video OCR Python projects. You write code to extract frames, preprocess them, and feed them to Tesseract.
Type: Open-source library (runs locally)
Price: Completely free and open-source
Pros: No cost, full control over the pipeline, runs offline, active community, supports 100+ languages, extensive documentation
Cons: Requires Python programming, lower accuracy than cloud APIs on complex backgrounds, you build and maintain everything yourself, no GUI
Best for: Developers who want complete control and don’t mind building a pipeline from scratch
6. Snagit
Snagit by TechSmith is a screen capture tool with a built-in OCR function for grabbing text from screenshots. It works on images, not full video files. You’d need to manually capture screenshots from your video and run OCR on each one individually.
Type: Desktop application (Windows/Mac)
Price: $39/year subscription. Free trial available.
Pros: Simple interface, good for quick screenshot OCR, integrates with TechSmith’s other tools, works offline
Cons: Not designed for video — images only, manual frame capture required, no batch processing, no timestamp mapping
Best for: Users who only need text from a few screenshots, not full video processing
7. Azure Video Indexer
Azure Video Indexer combines speech transcription, face detection, and OCR into one enterprise platform. It processes whole video files and extracts multiple types of metadata at once.
Type: Enterprise cloud API
Price: Free trial: 10 hours (web) or 40 hours (API). Paid tiers: Basic, Standard, and Advanced with per-minute pricing. Requires Azure subscription.
Pros: Full video analysis (OCR + speech + faces + objects), enterprise reliability, integrates with the Microsoft ecosystem, processes video files directly
Cons: Requires Azure account and technical setup, complex pricing, overkill for simple text extraction, steep learning curve
Best for: Large organizations processing thousands of videos that need OCR alongside other video intelligence features
8. Twelve Labs
Twelve Labs is a multimodal video AI platform that goes beyond traditional OCR. It analyzes video frames in context, understanding how text relates to what’s happening visually — similar to how GPT-4o processes images, but applied across an entire video timeline.
Type: Video AI API
Price: 600 minutes of video free. Developer plan starts at $0.033/minute for indexing.
Pros: Context-aware analysis across frames, multimodal understanding (text + visual + audio), generous free tier, modern API design
Cons: Newer platform with smaller community, requires API integration, costs scale with long videos
Best for: Developers building video search or analysis features who need OCR as part of a larger system
Who Needs Video OCR?
Video OCR solves practical problems across different industries and roles.
HR and Training Teams
Convert silent screen recordings of software tutorials into written SOPs. Record your screen, run Video OCR, and get a complete step-by-step guide without manual documentation.
Students and Educators
Pull all the text from a lecture's presentation slides without copying by hand. Use video OCR online to get every slide's content into your notes in minutes.
Developers and QA Teams
Extract error messages, log output, and UI text from bug report videos. Run OCR on a screen recording to get searchable text instead of scrubbing through video manually.
Try ScreenApp Video OCR
If you’re tired of pausing videos and manually retyping on-screen text, try ScreenApp. The free tier lets you test video OCR on your own files. Upload a video, enable the OCR option, and get a formatted document in a few minutes. You can combine OCR with audio transcription if your video has both spoken and visual content, or use video-to-document conversion for a complete written record.
FAQ
Is AI-powered OCR better than traditional OCR?
Yes. Traditional OCR recognizes characters using pattern matching, which struggles with messy backgrounds and unusual fonts. AI-powered OCR uses deep learning models that understand context, so they handle distorted text, complex layouts, and handwriting more accurately. According to Google’s research, deep learning models achieve 95%+ accuracy compared to 70-80% with older methods. Foundation models like Google Cloud Vision and PaddleOCR have significantly outperformed Tesseract on complex video frames.
Can I extract text from video on my phone?
Yes, partially. iOS has Live Text and Android has Google Lens. Both can read text from your camera or photos, but neither processes entire video files automatically. They work on single images or live camera feeds. For full video OCR (every frame of a video file), you need a tool like ScreenApp that processes the whole file and consolidates the text.
Is Google OCR free?
Google Lens is free for personal use on photos and live camera. The Google Cloud Vision API gives developers 1,000 free image analyses per month, then charges $1.50 per 1,000 images. New accounts get $300 in free credits. For video OCR specifically, their Video Intelligence API has separate per-minute pricing.
Can ChatGPT extract text from video?
Not automatically. ChatGPT (with GPT-4o) can analyze individual images and read text from them, but you can’t upload a full video and have it process every frame. You’d need to manually screenshot each frame, upload images one by one, and then piece the text together yourself. A dedicated video OCR tool processes all frames automatically and produces one consolidated document — saving hours of manual work on even a short video.
What’s the difference between transcription and video OCR?
Audio transcription converts spoken words (the audio track) into text. Video OCR reads visible text (pixels on screen) and converts that into text. If someone is speaking, use transcription. If text is displayed on screen — menus, code, slides, subtitles — use OCR. ScreenApp can run both on the same video simultaneously to capture everything.
Can video OCR extract hardcoded subtitles?
Yes. Video OCR reads burned-in (hardcoded) subtitles the same way it reads any other on-screen text. The AI processes each frame and picks up the subtitle text automatically. This is useful when you need to translate subtitles, search dialogue, or repurpose content from videos where subtitles aren’t in a separate .srt file. For subtitle-specific extraction, also check out our guide on AI subtitle generators.
How accurate is video OCR?
On clear, high-resolution text (720p or above), modern video OCR using deep learning hits 95-99% accuracy. Accuracy drops with low video quality, unusual fonts, small text, or heavy visual effects. Cloud APIs like Google Cloud Vision and Azure generally outperform open-source Tesseract on difficult frames. If you’re working with low-quality recordings, video enhancement tools can improve results before running OCR.
Is there a free video OCR tool?
Several. Copyfish is a completely free, open-source browser extension that does OCR on paused video frames. Tesseract OCR is free but requires Python coding. ScreenApp has a free tier with limited credits. Microsoft PowerToys Text Extractor on Windows can also grab text from anything on screen, including paused videos.
What video formats work with video OCR?
Most video OCR tools accept common formats: MP4, MOV, AVI, WebM, and MKV. ScreenApp also accepts YouTube links and Google Drive files directly — you don’t need to download the video first. For developer tools like Tesseract, format support depends on your frame extraction library (OpenCV supports nearly every format).
Related Guides
- ScreenApp Video OCR Feature — Full overview of the video OCR capability
- Video to Document Conversion — Turn any video into Word, PDF, or PPT
- Video to Text Converter — Extract text from video files or URLs
- Video to PowerPoint — Convert video content into slide presentations
- Create SOPs from Video with AI — Turn screen recordings into standard operating procedures
- Best AI Subtitle Generators — Tools for generating and extracting subtitles
FAQ
Yes. Traditional OCR recognizes characters using pattern matching, which struggles with messy backgrounds and unusual fonts. AI-powered OCR uses deep learning models that understand context, so they handle distorted text, complex layouts, and handwriting more accurately. According to Google's research, deep learning models achieve 95%+ accuracy compared to 70-80% with older methods. Foundation models like
Yes, partially. iOS has Live Text and Android has Google Lens. Both can read text from your camera or photos, but neither processes entire video files automatically. They work on single images or live camera feeds. For full video OCR (every frame of a video file), you need a tool like ScreenApp that processes the whole file and consolidates the text.
Google Lens is free for personal use on photos and live camera. The Google Cloud Vision API gives developers 1,000 free image analyses per month, then charges $1.50 per 1,000 images. New accounts get $300 in free credits. For video OCR specifically, their Video Intelligence API has separate per-minute pricing.
Not automatically. ChatGPT (with GPT-4o) can analyze individual images and read text from them, but you can't upload a full video and have it process every frame. You'd need to manually screenshot each frame, upload images one by one, and then piece the text together yourself. A dedicated video OCR tool processes all frames automatically and produces one consolidated document -- saving hours of manual work on even a short video.
Audio transcription converts spoken words (the audio track) into text. Video OCR reads visible text (pixels on screen) and converts that into text. If someone is speaking, use transcription. If text is displayed on screen -- menus, code, slides, subtitles -- use OCR. ScreenApp can run both on the same video simultaneously to capture everything.
Yes. Video OCR reads burned-in (hardcoded) subtitles the same way it reads any other on-screen text. The AI processes each frame and picks up the subtitle text automatically. This is useful when you need to translate subtitles, search dialogue, or repurpose content from videos where subtitles aren't in a separate .srt file. For subtitle-specific extraction, also check out our guide on AI subtitle generators.
On clear, high-resolution text (720p or above), modern video OCR using deep learning hits 95-99% accuracy. Accuracy drops with low video quality, unusual fonts, small text, or heavy visual effects. Cloud APIs like Google Cloud Vision and Azure generally outperform open-source Tesseract on difficult frames. If you're working with low-quality recordings, video enhancement tools can improve results before running OCR.
Several. Copyfish is a completely free, open-source browser extension that does OCR on paused video frames. Tesseract OCR is free but requires Python coding. ScreenApp has a free tier with limited credits. Microsoft PowerToys Text E
Most video OCR tools accept common formats: MP4, MOV, AVI, WebM, and MKV. ScreenApp also accepts YouTube links and Google Drive files directly -- you don't need to download the video first. For developer tools like Tesseract, format support depends on your frame extraction library (OpenCV supports nearly every format).





